Наш адрес :
г. Минск, ул. Тимирязева 65А, офис 516
- Пн-Пт: 8:30-18:00
Сервис услуг электронного документооборота для юридических лиц и ИП
Беларусь
Крупный поставщик услуг электронного документооборота. Успешно работает на рынке более 5 лет. Свыше 20 000 организаций всех форм собственности пользуется его услугами. Среди известных клиентов: McDonalds, Евроопт, Conte, МТС и др. Одна из популярнейших систем ЭДО на территории РБ.
В связи с активным seo-продвижением сайта возникла необходимость актуализировать семантику под спрос. Поэтому ключевыми задачами стали:
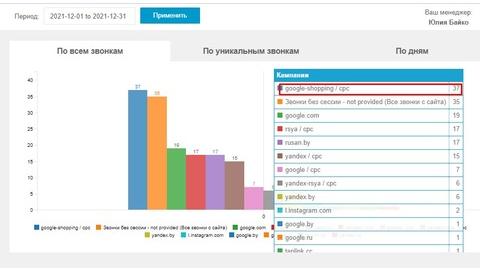
В связи с новизной услуги на рынке РБ, начиная с 2018 прослеживается постепенный рост трафика до мая 2019 года. После чего начинается спад в связи с отпусками в летний период. Под конец августа сезон отпусков заканчивается, спад постепенно уступает росту, который продолжается до конца декабря.

Высокая
1. Основной сложностью для ниши является очень высокий порог вхождения в тематику. Те, кто не связан с документооборотом, не сразу поймут значение и разницу между всеми аббревиатурами и терминами. Например:
- тн
- ттн
- этн
- эттн
- crm
- сд
- система документооборота
- смдо
- сэд
- црм
- эдо
- эцп
- эцпп
- контрагент
- црм
- цифровизация
- верификация
- эсф
- сдэо
2. Для качественного сбора и обработки семантики необходимо максимально детально и глубоко изучить нишу.
3. Типы ключей и их количество в тематике. Распределение следующее: большинство из ключевых слов информационные, далее спектральные, а на последнем месте коммерческие.
4. Для повышения ширины и глубины СЯ, помимо стандартных методов сбора, необходимо применить необычные для региона способы, такие как: парсинг елочки (для увеличения глубины СЯ), обработка выгрузки ( для увеличения ширины с помощью запросов из контекста), парсинг подсказок (для повышения объема информационных запросов) – все эти методы будут описаны далее.
5. При парсинге собирается большое количество нецелевых информационных запросов. Поскольку одна из задач клиента – собрать целевые информационные запросы, необходимо просеять, изучить и использовать каждый запрос только после их согласования.
Из-за обилия статей в блоге на сайте возникает проблема при определении релевантных URL-адресов для групп ключевых слов на финальном этапе кластеризации.
Из-за сложной и узкой тематики было решено задействовать дополнительные инструменты и способы сбора семантического ядра:
Актуальный инструмент для увеличения объема СЯ в контекстной рекламе или для получения информационных КС в семантике для SEO. Был применен для поиска актуальных информационных КС.
После получения конечной чистовой семантики все ключи отправляются на парсинг подсказок из ПС Яндекс. Google не используется, поскольку собирает много ненужной информации. Затем проводится повторная минусация.

Итог: 58 дополнительных целевых ключевых слов.
Инструмент для повышения объема семантики за счет увеличения глубины. Заключается в отправке на парсинг повторяющихся запросов в уточненном вхождении.
При отправке запросов в Wordstat, в выдаче мы получаем лишь те, что содержат это слово или словосочетание, повторяющееся равноценное количество раз до семи включительно.
Пример:

После создания и выбора всех пересечений они отправляются на парсинг левой колонки Wordstat.
Клиент активно использует поисковую контекстную рекламу и имеет установленные на сайте Яндекс.Метрику и Google Analytics. Для увеличения объема и ширины СЯ из рекламных кабинетов были выгружены поисковые запросы, по которым люди переходили за все время работы контекстной рекламы.
Кроме этого, охватили и наработки по SEO: из Яндекс.Метрики были выгружены все поисковые запросы, по которым были переходы из органической выдачи Яндекса.
Общий объем выгрузок составил более 15 000 живых поисковых запросов. Далее произвели сортировку по значениям через фильтры неявных дублей и стоп-слов. А затем провели ручной отбор целевых запросов для использования в SЕО СЯ. Также выгрузка использовалась на этапе генерации для расширения столбцов пересечений.
Итог: получили 107 дополнительных КС.
Сперва выполнили генерацию, в которой использовались выгрузки из метрики и рекламных кабинетов.

Для создания генерации в подобной тематике необходимо детально изучить сферу до уровня понимания аббревиатур и общих терминов. Четко определить целевые услуги и интересующие, проблемные темы для потенциальных клиентов.
Далее сформировали пересечения столбцов генерации до 4 включительно, поскольку необходимо получить максимальную глубину.

После завершения формирования пересечений, на съем частотности было отправлено 160 404 КС.

На парсинг отправились 11 446 КС. В их число не вошли слова с нулевой частотность.
Итоги пакетного сбора черновой семантики: 111 570 КС с суммарной базовой частотой 2 557 575.

Следующим этапом была выполнена минусация семантического ядра до состояния чистовой семантики. На этом этапе проводятся процедуры удаления нецелевых фраз из ядра: пропуск через заготовленные слова общих тематик, ручная чистка, проверка интентов, поиск неявных дублей, отсеивание пустышек, приведение к правильной словоформе.
Для этого этапа необходимо заранее заготовить, расширить и оптимизировать список стоп-слов. Определить и согласовать с клиентом нецелевые тематики.

После завершения минусации и корректировки, в соответствии с обратной связью от клиента, получено 761 целевых КС.

Интент пользователя – самый главный фактор распределения ключевых фраз по кластерам. Контент страницы должен максимально соответствовать желанию пользователя вводящего запрос, будь это информационная статья или каталог с товарами. Исходя из этого группируются запросы с одинаковым интентом.
Сформированность выдачи – фактор, который определяет, чем следует руководствоваться при создании кластера. Если выдача не сформирована, руководствуемся только логикой и интентом пользователя. Если выдача полностью сформирована, следует создать кластер согласно интенту ПС, отодвигая логику в сторону.
На этапе кластеризации следует отдельно проверять по выдаче каждое ключевое слово.
Особенностью этого сбора СЯ на этапе кластеризации стала необходимость распределения части информационных КС по уже имеющимся статьям блога на сайте клиента.
Собрано новое семантическое ядро под актуальный спрос. Несмотря на узость ниши, объем целевых ключевых слов составил 761. По итогам кластеризации было создано 302 кластера. Сформированы 44 новые темы для информационных статей в блог.

Другие наши кейсы








.47e4bb40847d814ac2119357cffc1c51103.jpg)